@ARTICLE{varol24_hdr,
title = {Bridging Language and Dynamic Visual Data},
author = {G{\"u}l Varol},
school = {Institut Polytechnique de Paris (IPP)},
note = {Habilitation thesis},
year = {2024}
}
In the past decades, the fields of computer vision and natural language processing have evolved concurrently, albeit somewhat independently. Recent developments have witnessed a convergence between these two domains, both in terms of cross-inspiration for method development and the creation of unified frameworks capable of handling diverse data types, such as images and text. This manuscript outlines our recent research at the intersection of vision and language, with a particular focus on \textit{dynamic} visual data, including videos and 3D human motions. Our contributions encompass three key areas: (i)~generative modeling for text-to-human motion synthesis, (ii)~addressing training data scarcity for text-to-video retrieval, and (iii)~automatically annotating sign language videos with text. The common denominator among these contributions is the inclusion of text in the tasks we address. Despite differences in data sources and domain knowledge for task-specific solutions, our methodologies share common tools such as visual sequence modeling with transformers, contrastive learning for retrieval scenarios, and leveraging large language models for text modeling. The manuscript is organized into three main chapters to present these contributions.
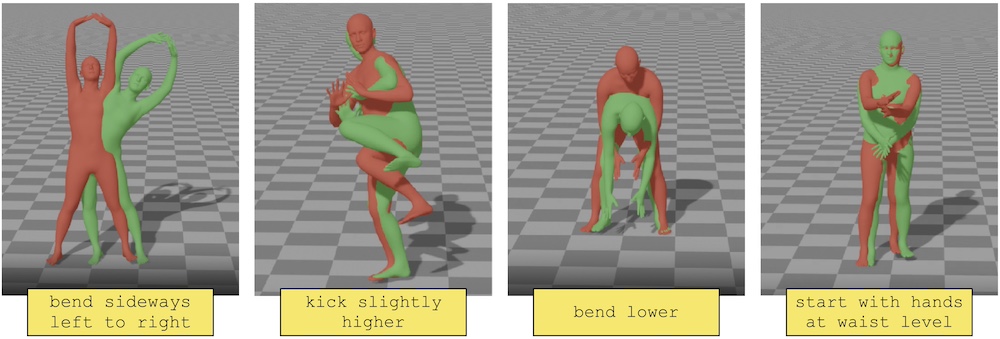
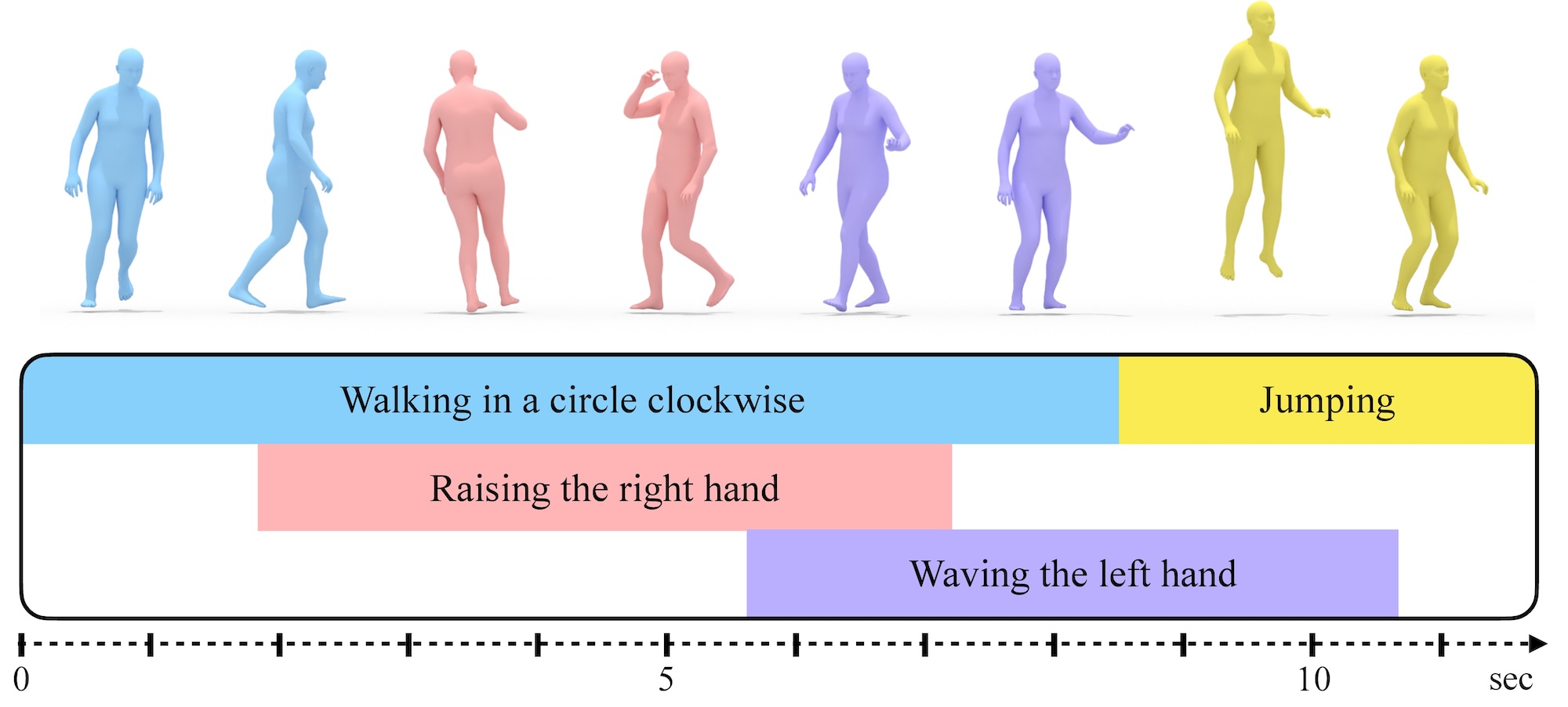
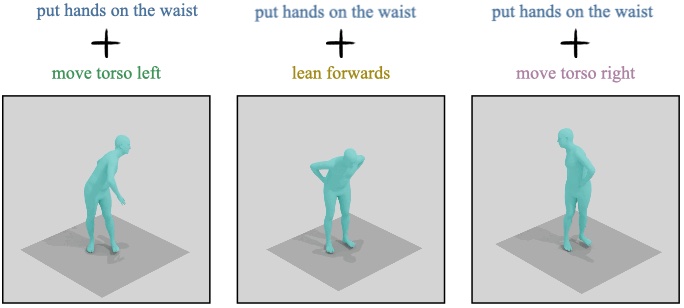
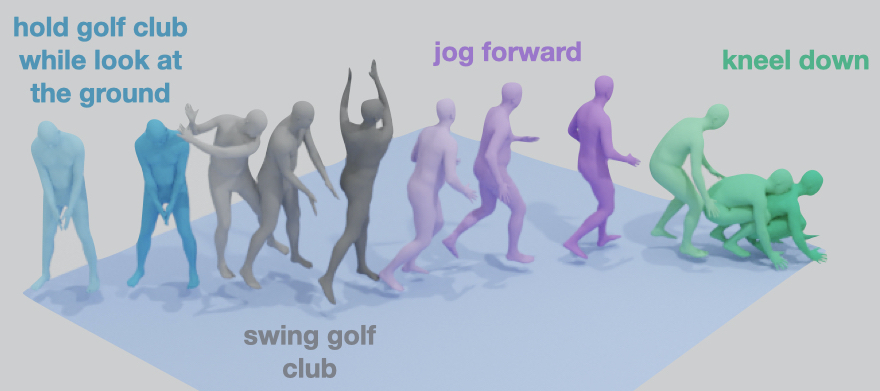
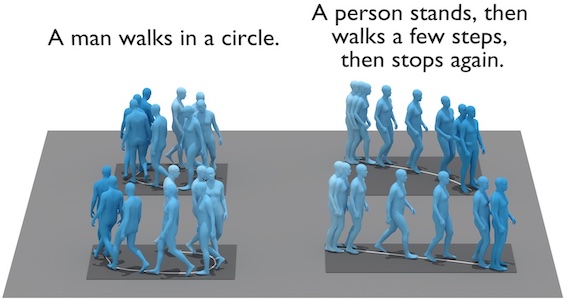
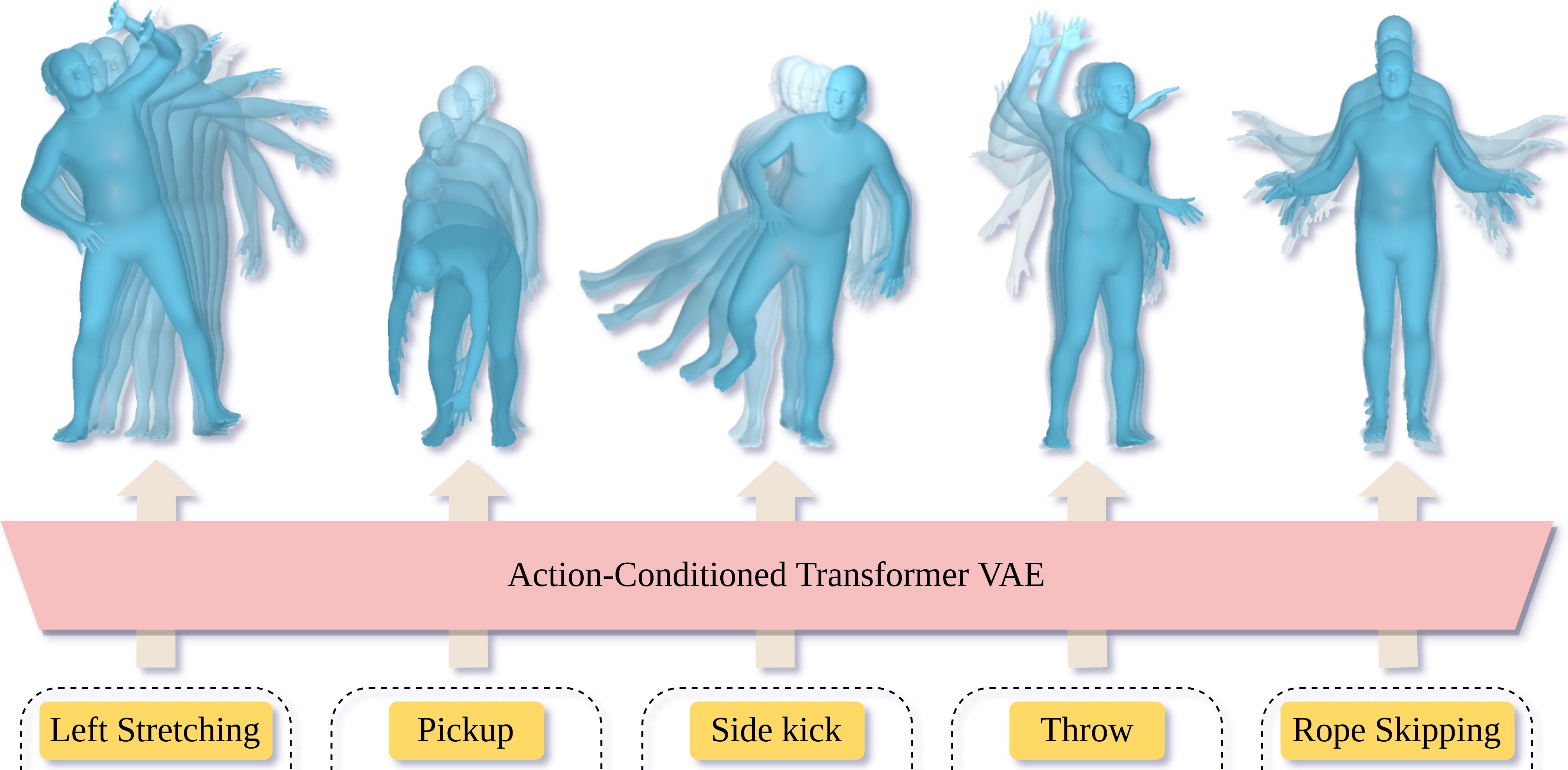
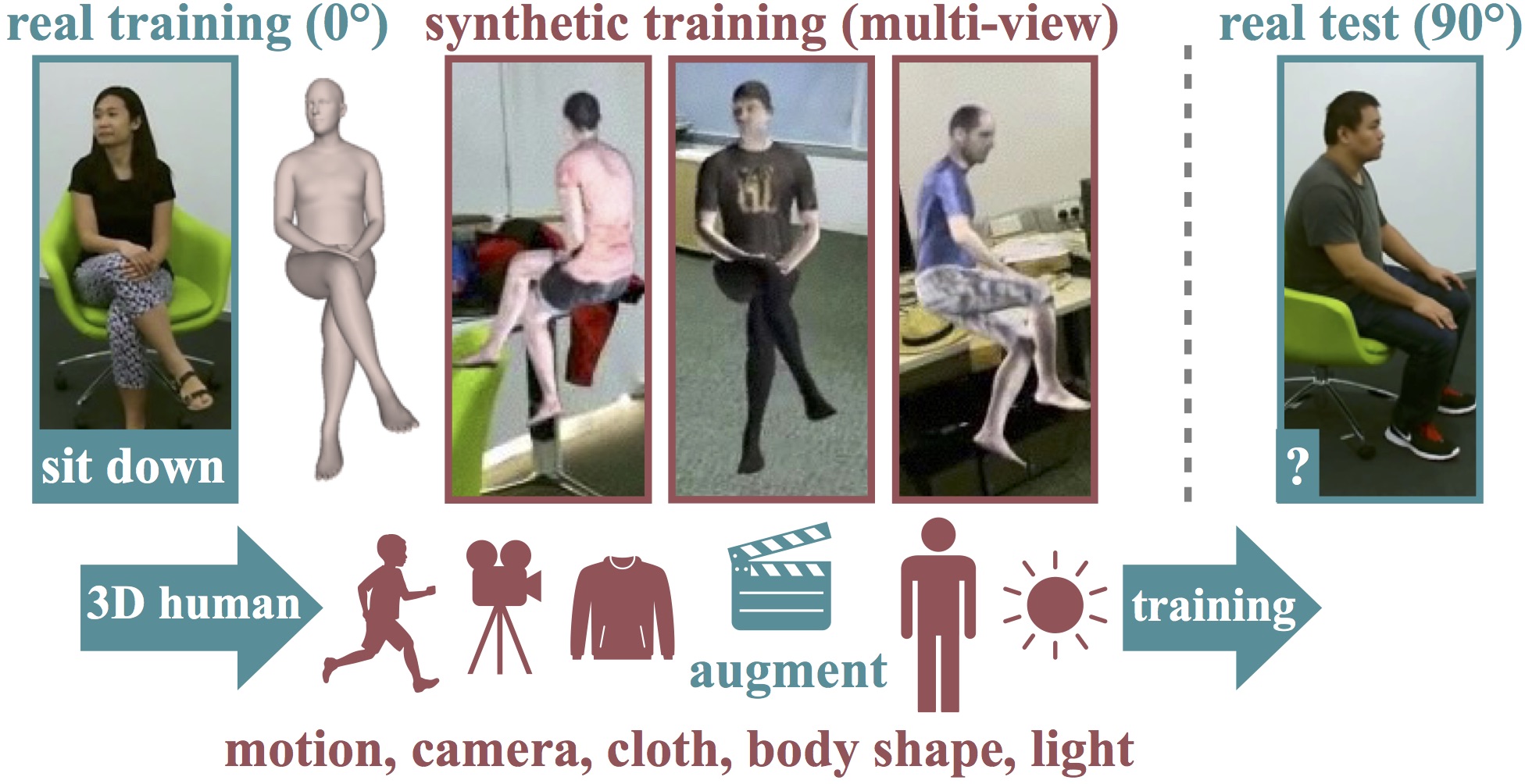
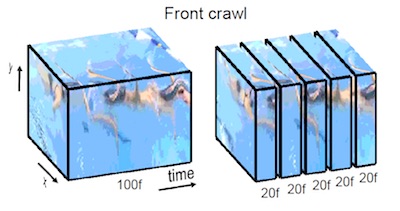
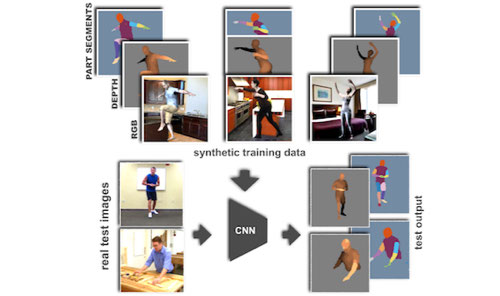
In the first part, we delve into human motion synthesis, posing the question: is human motion a language without words? More specifically, can human motions be described or controlled by words? As an effort to answer this question, we develop methods for generating 3D human body movements given textual descriptions. Each work presented in this chapter investigates increasing granularity towards finegrained semantic control, allowing simultaneous and series of actions. Our approaches employ variational autoencoders with transformer architectures, representing 3D motion as a sequence of parametric body models. The promising results underscore the potential of text-conditioned generative models in this domain, while limitations point to the need for future work on scaling up training data to unlock a broader vocabulary of action descriptions.
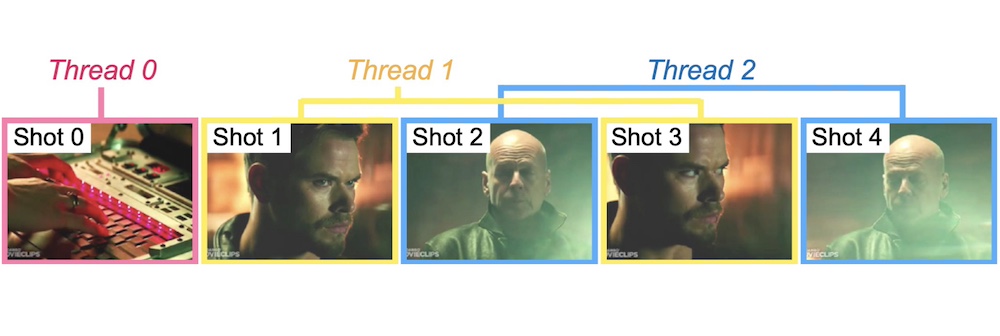
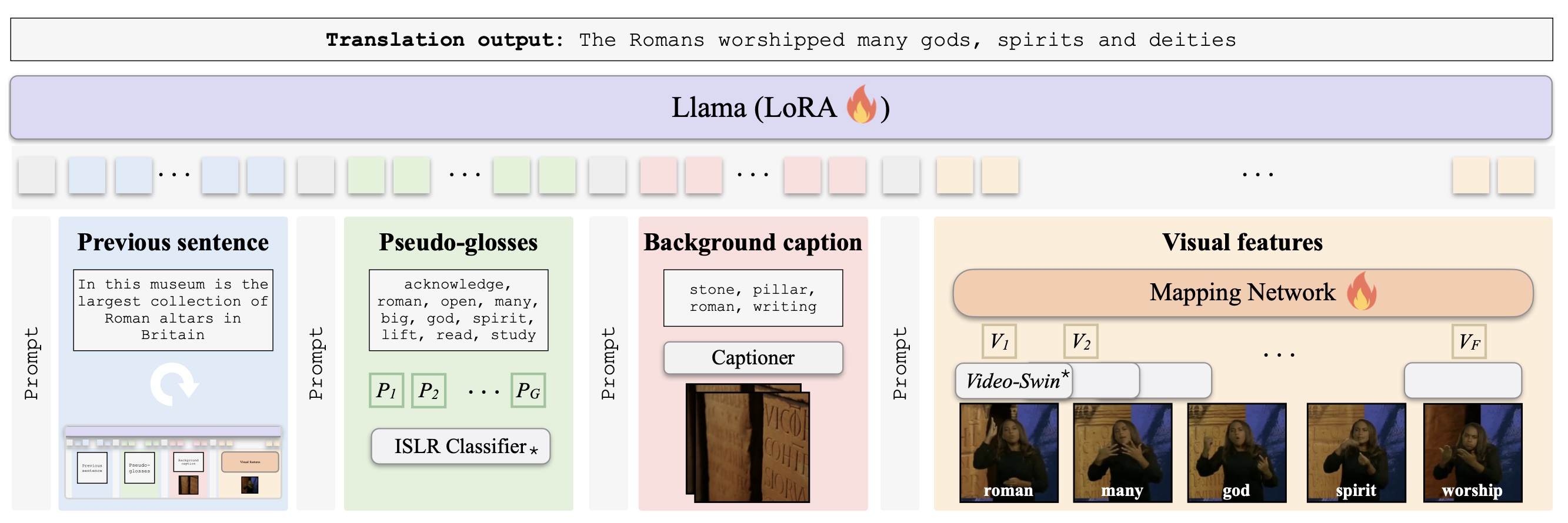
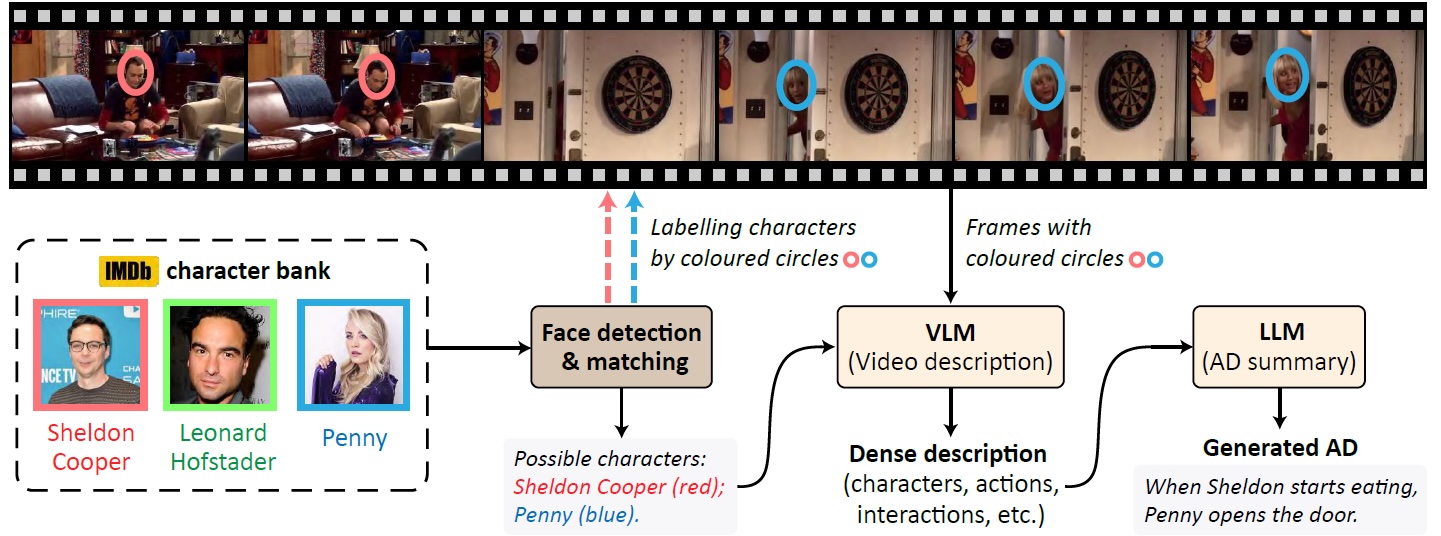
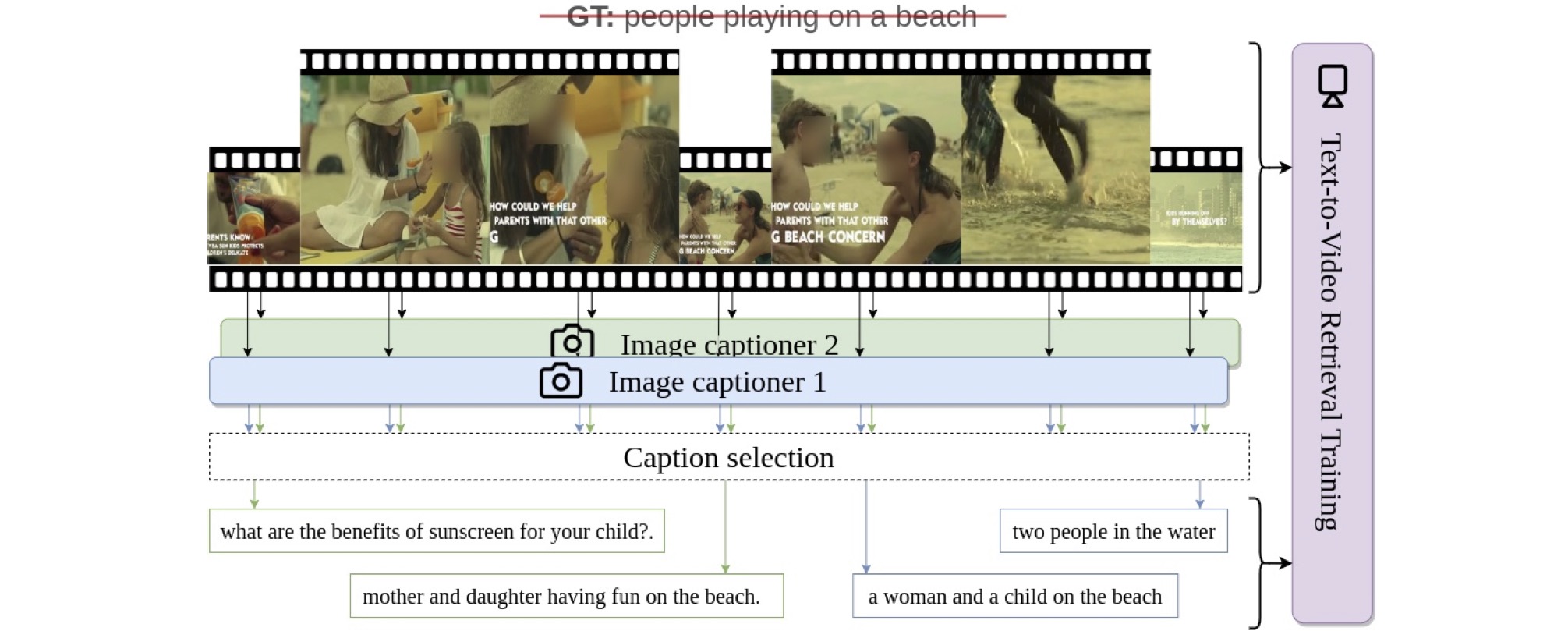
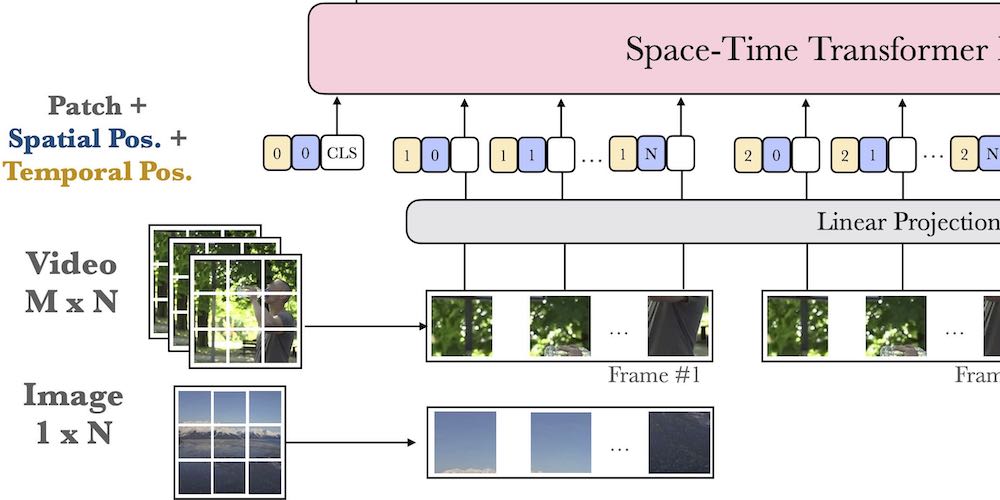
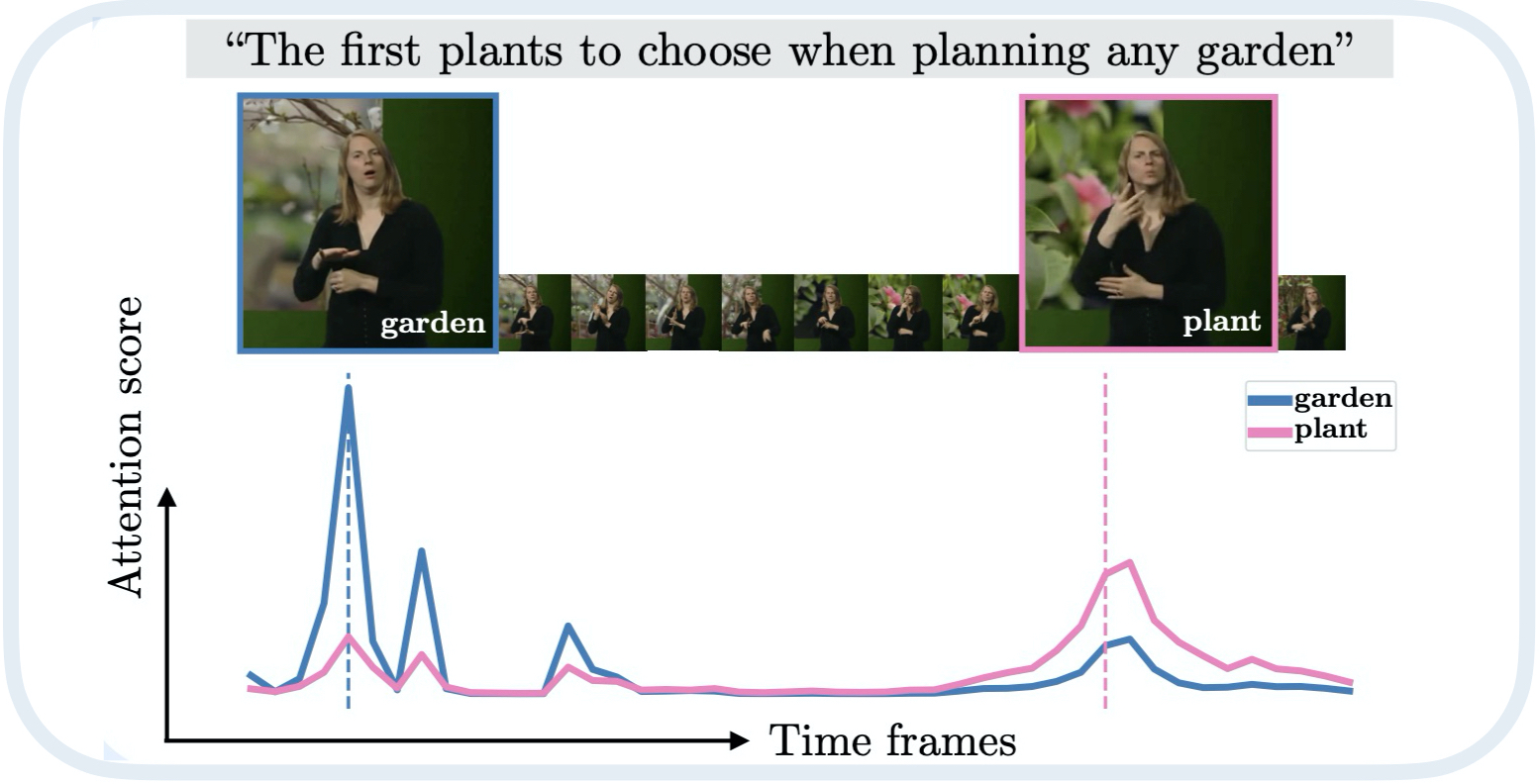
The second part emphasizes bridging video data and language, addressing challenges posed by limited annotated data in the video domain. We introduce strategies to overcome training data scarcity, including a large-scale collection of captioned web videos which allows for end-to-end video representation learning via text supervision. Additionally, we automate the annotation of text-video pairs for cross-modal retrieval training, using image captioning models on video frames. Similarly, we automatically construct image-text-video triplets for training video retrieval from composite image-text queries. Our focus extends to automatic audio description generation for movies, which can be seen as a form of long video captioning in the context of a story. Here, we employ partial training strategies by combining various sources of training data, such as text-only movie descriptions.
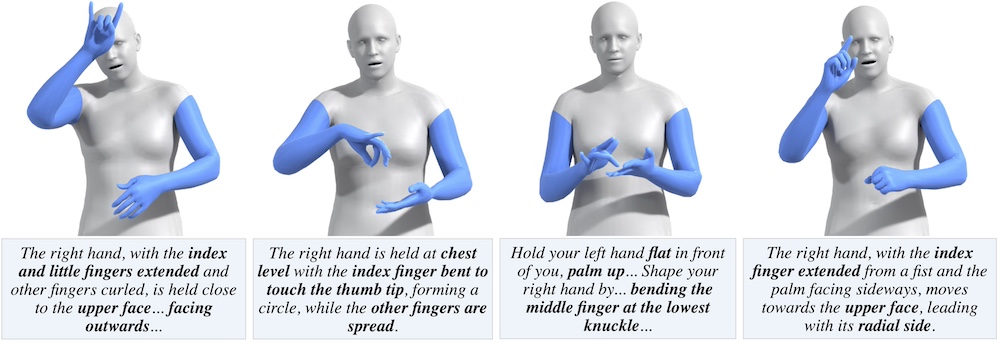
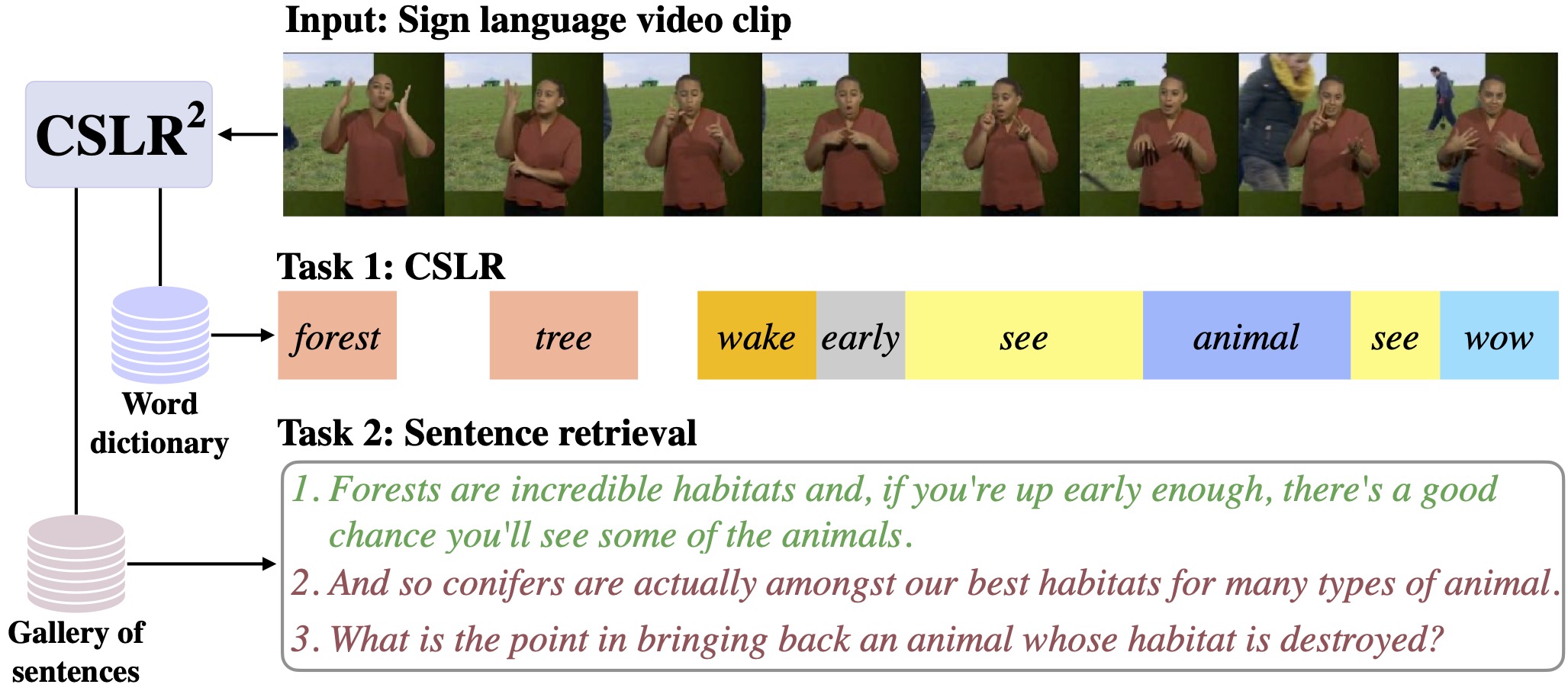
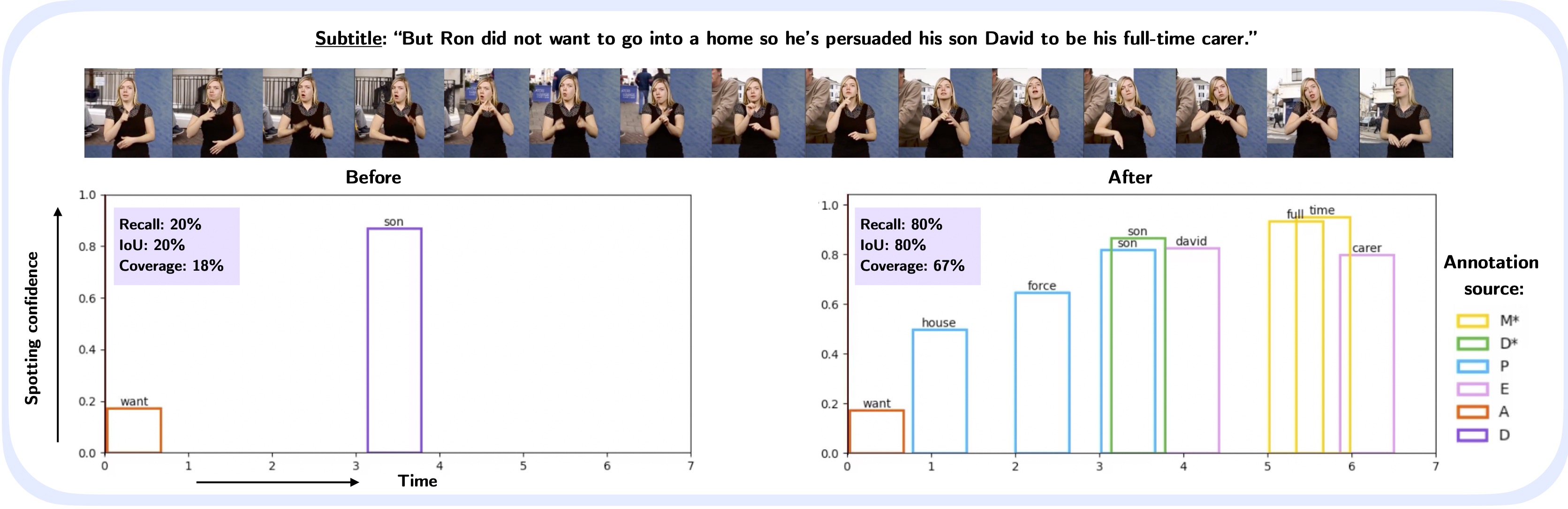
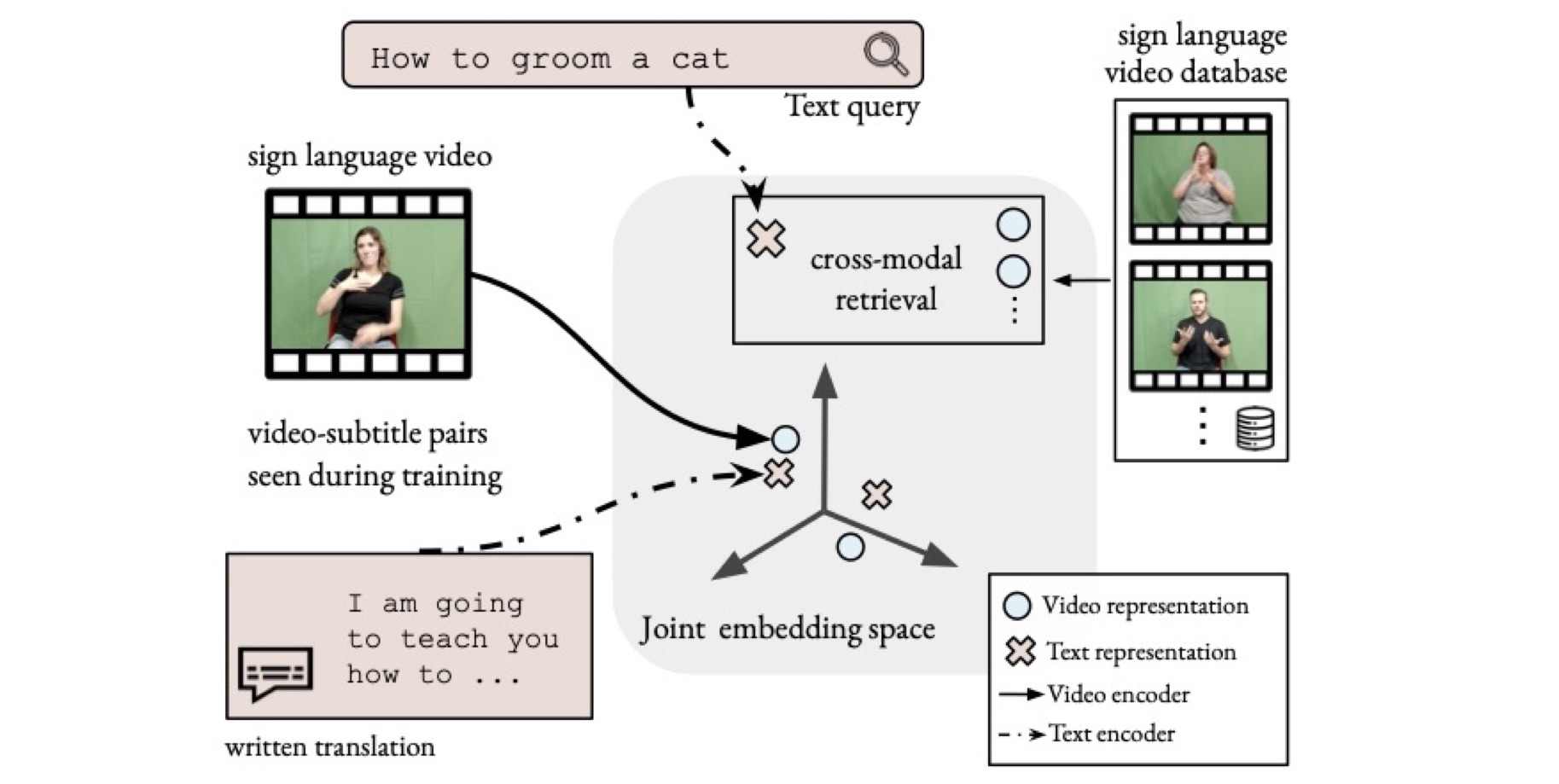
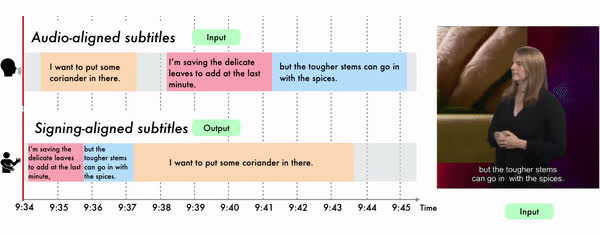
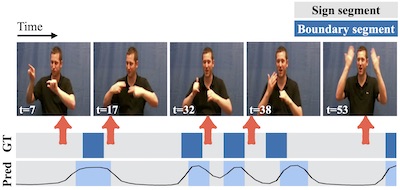
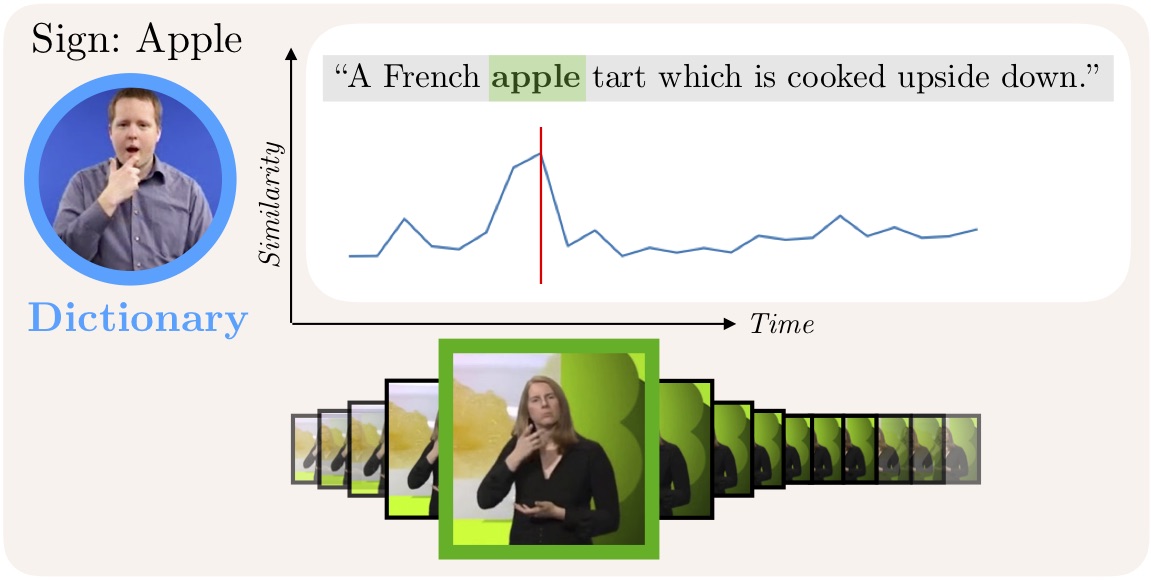
In the third and final part, we focus on sign language as a unique form of video inherently conveying language. Our works in this chapter span tasks such as temporal localization of signs, subtitle alignment, text-based retrieval, temporal segmentation as a form of tokenization, signer diarization, and fingerspelling detection. These studies represent pioneering attempts to scale up computational sign language analysis in an open-vocabulary setting.
This manuscript is intended to offer an overview of the aforementioned research efforts, framing each work within the broader context of our exploration of dynamic vision and language. Further details can be found in the corresponding publications, and the reader is encouraged to refer to them for additional insights.
- David Forsyth, University of Illinois Urbana-Champaign (reviewer)
- Kristen Grauman, University of Texas at Austin (reviewer)
- Jean Ponce, École Normale Supérieure - PSL (reviewer)
- A. Alyosha Efros, University of California Berkeley (examiner)
- Patrick Perez, Kyut.ai (examiner)
- Andrew Zisserman, University of Oxford (examiner, collaborator)
- Michael J. Black, Max Planck Institute (examiner, collaborator)
- Cordelia Schmid, Inria (examiner, collaborator)

















{kind=link}